
티스토리 뷰

(한빛미디어에서 모집하는 혼공학습단 활동의 일환으로 혼자 공부하는 머신러닝+딥러닝 책을 공부하고 작성한 글입니다. 책은 제 돈으로 샀습니다. 본문의 코드는 책의 소스코드를 기반으로 하되 글 흐름에 맞게 수정한 것입니다. 원본 코드는 저자 박해선 님의 깃허브에서 보실 수 있습니다. 책에 나오는 넘파이, 판다스 등의 내용은 본 글에는 넣지 않았습니다.)
수상한 100점
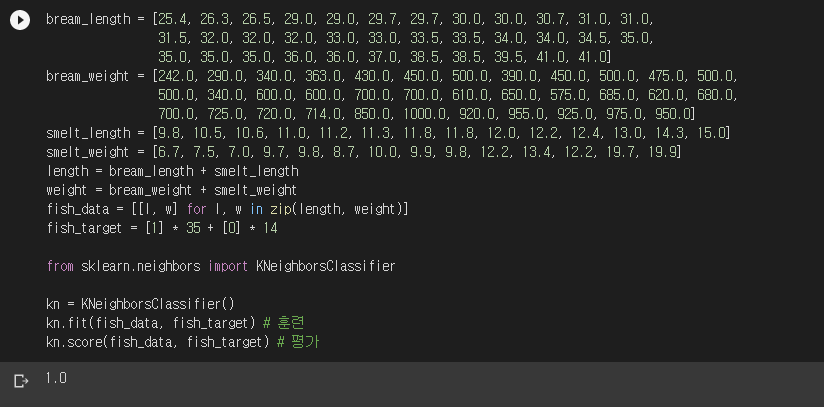
1장에서 생선 데이터(fish_data)와 정답(fish_target)을 이용해서 K-NN을 훈련시켰습니다. 그리고 동일한 데이터로 평가까지 진행했습니다. 스코어가 1.0이 나와서 행복했었죠.
그런데 조금만 생각해보면 이상하다는 걸 알 수 있습니다. 훈련과 평가를 같은 데이터로 해도 될까요? 외계인에게 사진만 보고 개인지 고양이인지 맞추게 하고 싶은데, 개/고양이 사진을 각각 100장 보여주고 미리 보여준 사진으로만 평가를 한다면 당연히 100점이 나오지 않을까요? 이런 방식으로는 정말 훈련되었다고 볼 수 없습니다. 그냥 답을 외운 것뿐이지, 개/고양이 분류법을 익힌 것이 아니죠. 제대로 평가하려면 훈련용 사진에 없던 사진을 보고 맞춰야 합니다.
머신러닝 알고리즘은 정답을 미리 알려주고 훈련시키는 지도 학습supervised learning, 정답을 모르고 훈련하게 하는 비지도 학습unsupervised learning으로 나눌 수 있습니다. 지금까지 했던 K-NN은 정답-도미인지 빙어인지-을 알려줬으니 지도 학습입니다. 1장 내용정리 말미에 잠깐 언급한 k-평균 알고리즘은 정답은 모르지만 알아서 군집을 나누게 시키는 비지도 학습입니다. k-평균 알고리즘은 6장에서 보다 자세히 다룰 예정입니다.
지도 학습에서 데이터(생선의 길이와 무게)를 입력input, 정답(도미 또는 빙어)을 타겟target이라고 부릅니다. 이 둘을 합쳐서 훈련 데이터training data라고 부릅니다. 입력으로 사용된 생선의 길이와 무게는 특성feature이라고 부릅니다. 앞에서 언급했듯이 제대로 훈련하려면 훈련에 사용한 데이터와 평가에 사용하는 데이터가 달라야 합니다. 훈련에 사용하는 데이터를 훈련 세트training set, 평가에 사용하는 데이터를 테스트 세트test set라고 부릅니다.
[용어]
입력input: 지도 학습에 사용하는 데이터
타겟target: 지도 학습에서 사용하는 정답
훈련 데이터training: 지도 학습에서 사용하는 입력과 타겟
특성feature: 입력으로 사용된 각각의 값
훈련 세트training set: 훈련에 사용하는 데이터
테스트 세트test set: 평가에 사용하는 데이터
훈련 세트와 테스트 세트로 나누기
훈련과 평가를 아래처럼 했었죠.

KNeighborsClassifier의 메서드 중 fit()으로 훈련을, score()로 평가를 진행했습니다. 이 코드의 문제는 훈련과 평가에 동일한 데이터를 썼다는 점이었죠. 49마리 생선의 전체 데이터를 훈련 세트와 테스트 세트로 나눠보겠습니다.
여기서 주의할 점이 있습니다. 전체 데이터는 35마리의 도미 데이터, 14마리의 빙어 데이터가 순서대로 들어있습니다. 즉, fish_data[:35]에는 도미가, fish_data[35:]에는 빙어가 들어있습니다. 이때 훈련 세트와 테스트 세트를 아래처럼 하면 어떻게 될까요?

0점이 나오네요. 당연한 결과입니다. 외계인에게 고양이 사진만 100장 보여주고 나서 갑자기 강아지 사진을 들이밀고 “이게 뭐게?”라고 물으면 외계인은 고양이라고 답할 겁니다. 개 사진은 본 적이 없거든요.

K-NN은 새로운 데이터가 들어오면 가까운 곳에 어떤 데이터가 있는지 찾아보고 분류합니다. 지금 kn에는 이렇게 도미 데이터만 들어있습니다. 빙어 데이터는 알지 못합니다. 그러니 새 데이터가 들어오면 무조건 도미로 분류하겠죠.
상식적으로 훈련하는 데이터와 테스트하는 데이터에는 도미와 빙어가 골고루 섞여 있어야 합니다. 일반적으로 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미로 샘플링 편향sampling bias이라고 부릅니다.
박해선, 혼자 공부하는 머신러닝 + 딥러닝, 한빛미디어, 73쪽
훈련이 제대로 되려면 전체 데이터의 도미:빙어 비율이 훈련 세트와 테스트 세트에도 고스란히 유지되어야 합니다. 전체 데이터를 랜덤으로 섞으면 어떨까요? 넘파이numpy의 shuffle()을 이용해 보겠습니다.

파란색이 훈련 세트, 주황색이 테스트 세트입니다. 잘 나눠진 것 같긴 한데, 확인은 해봐야겠죠?

비율이 조금 안 맞군요. 전체 데이터는 도미:빙어가 35:14 = 5:2이므로 테스트 세트 14개 중 10개가 도미여야 합니다. 그런데 실제로 확인해보니 도미가 8마리밖에 안 들어있네요. 사이킷런에는 이 문제를 한방에 해결해주는 함수가 이미 준비되어 있습니다. train_test_split()을 stratify 파라미터와 함께 사용하면 원본 데이터의 비율을 유지하며 훈련/테스트 세트를 나눠주고 랜덤으로 섞어주기까지 합니다.
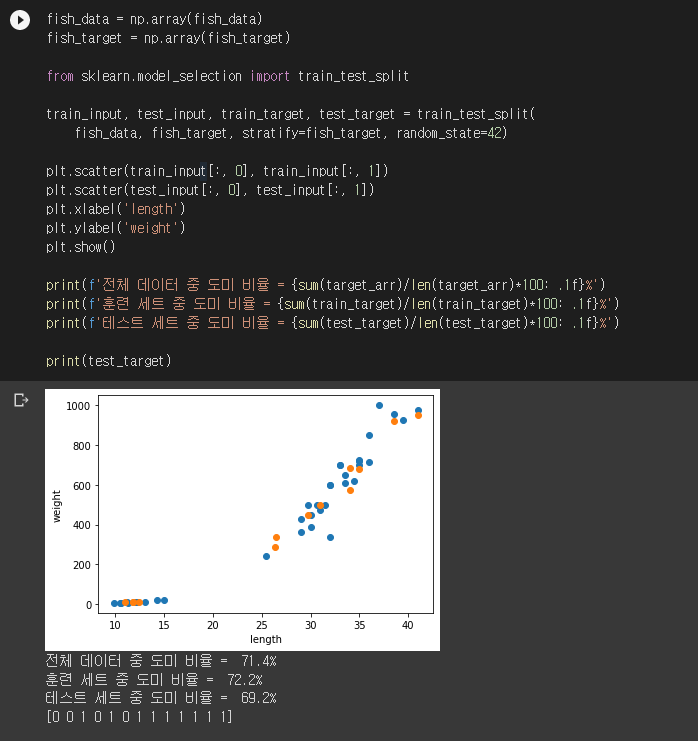
여전히 살짝 안 맞는데, 여기엔 이유가 있습니다. train_test_split()은 기본적으로 전체 데이터 중 25%를 테스트 세트로 할당합니다. 49의 25%면 12.25인데 test_target의 길이가 13인 걸 보니 올림을 하나 봅니다. 칼같이 맞추려면 train_test_split()의 파라미터로 test_size를 지정하면 됩니다. 여기서는 전체 49개 중 14개를 테스트 세트로 만들고 싶으니 test_size=2/7을 넣으면 되겠네요. 일단은 책에서는 거기까지는 하지 않았으니 그냥 이 상태로 두도록 하겠습니다. 자세한 내용은 레퍼런스 페이지를 참고해주세요. 어쨌든 잘 섞인 듯하니 다시 훈련 및 평가를 해보겠습니다.

잘 되는군요. 훈련 fit()과 평가 score()에 다른 데이터를 넣었는데도 답을 잘 찾았습니다. 그래프로도 확인해보겠습니다.
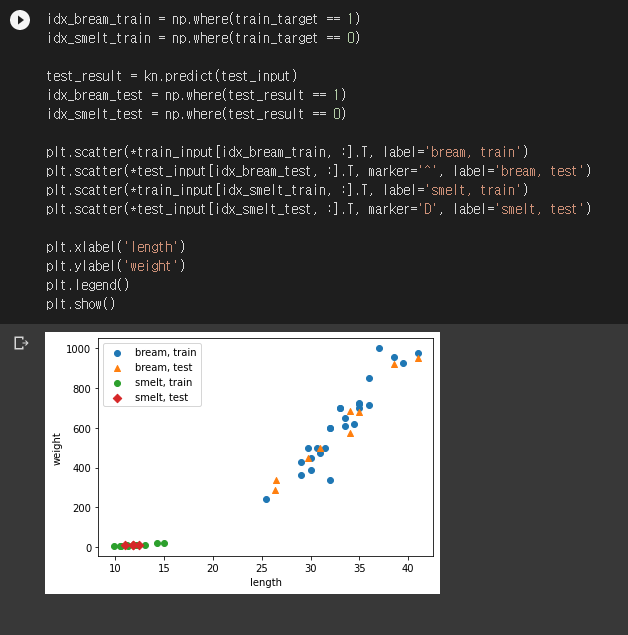
도미 테스트 세트는 도미로, 빙어 테스트 세트는 빙어로 잘 분류되었습니다. 예이- plt.scatter()를 좀 더 깔끔하게 쓰는 방법을 알려주신 페가님께 감사말씀 드립니다. 리스펙트!
숫자의 스케일에 조심하라
재밌는 문제를 하나 만들어보겠습니다. 길이가 25cm이고 무게가 150g인 생선은 도미와 빙어 중 무엇일까요?
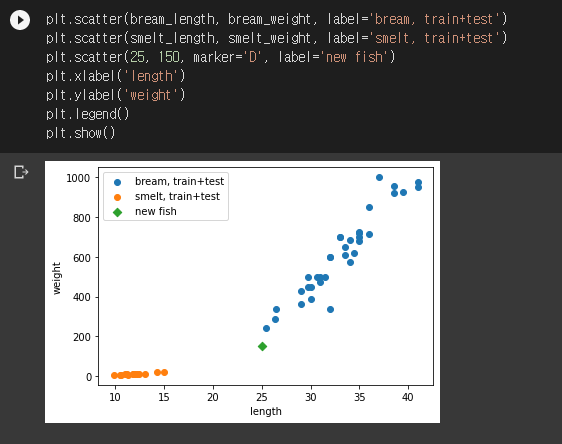
아무리 봐도 도미여야 할 것 같죠?

어라? 0이라 함은 빙어로 분류했다는 뜻입니다. 왜 그럴까요? 본 절의 제목처럼 숫자의 스케일에 조심해야 합니다.
K-NN은 우리말로 k-최근접 이웃 알고리즘입니다. 새로운 데이터가 들어오면 최근접 데이터가 무엇인지를 살핍니다. 즉 다른 데이터와의 거리를 계산합니다. 피타고라스의 정리로 계산되는 바로 그 거리입니다. 좀 유식한 말로는 유클리드 거리라고도 합니다. 위 그래프에는 함정이 있습니다. 무게 숫자(y축)가 길이 숫자(x축)보다 훨씬 큽니다. 따라서 화면 상으로는 x축의 길이가 과장되어 있습니다. 그래프에서 시각적으로 보이는 거리는 숫자로 계산되는 실제 거리와 큰 차이를 보일 겁니다. 두 축 스케일을 맞춰서 다시 그리고, 새로운 데이터와 가까운 5개가 어디에 있는지 표시해보겠습니다. KNeighborsClassifier의 kneighbors() 메서드는 새로운 입력과 가까운 데이터까지의 거리와 인덱스를 반환해줍니다.

역시! 함정카드 발동! 스케일을 1:1로 맞추니 새로운 데이터와 가까운 5개의 점 중 4개가 빙어네요. 길이 숫자의 스케일이 너무 작아서, 다른 점들과의 거리를 구할 때 길이는 거의 기여를 하지 못합니다. 즉 사실상 무게만으로 분류를 하고 있었던 거죠. 만약 무게가 그램이 아니라 킬로그램이었다면 반대로 길이만으로 분류를 했을 겁니다.
혹시 새로운 데이터를 분류할 때 최근접 데이터 1개만 보라고 하면 어떻게 될까요? KNeighborsClassifier의 n_neighbors 값을 직접 바꾸면 최근접 데이터를 몇 개 볼지 정할 수 있습니다.
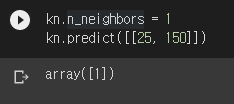
도미로 분류합니다. 어쨌든 가장 가까운 점은 도미이기 때문입니다. 하지만 이 방법은 다른 문제를 일으킬 가능성이 높습니다. 확실한 방법은 스케일을 맞추는 것입니다.
데이터 전처리 – 스케일 맞추기
스케일을 맞춘다는 것은 길이와 무게가 데이터 간의 거리에 기여하는 정도를 비슷하게 맞춘다는 것과 같은 말입니다. 이런 식으로 머신러닝은 학습 이전에 데이터를 마사지해주는 과정이 필요합니다. 학습 이전에 일어나는 데이터 처리 과정을 통칭하여 데이터 전처리data preprocessing라고 부릅니다. 가장 흔히 사용하는 방법은 표준점수standard score입니다. z 점수라고도 부릅니다. 사실 별 것 없고, 평균을 빼서 평균을 0으로 맞추고 표준편차로 나누면 끝입니다. 이런 그림은 다들 익숙하시죠?
[용어]
데이터 전처리data preprocessing: 학습 이전에 특성값을 일정한 기준으로 맞추는 작업
표준점수standard score: 특성값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지를 나타내는 값
넘파이를 이용해서 아래와 같이 훈련 세트와 테스트 세트의 스케일을 맞춰줍니다.

이제 두 세트 모두 평균이 0이고 표준편차가 1이 되었을 겁니다. 확인해보겠습니다.
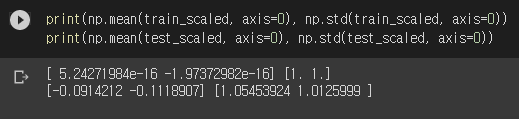
테스트 세트는 약간 맞지 않은데, 자연스러운 현상입니다. 평균과 표준편차를 훈련 세트로 계산했기 때문이죠. 이제 훈련과 평가를 해보겠습니다. 아까 테스트를 위해 바꿨던 n_neighbors도 다시 원래대로 5로 바꿉니다.

여기까진 잘 되는군요. 진짜 테스트 해볼 것은 따로 있죠. 맨 처음에 나왔던 길이 25cm, 무게 150g인 생선입니다. 당연한 얘기지만 이 생선도 스케일을 맞춰줘야 합니다.
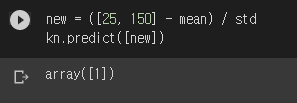
도미가 나왔습니다! 드디어 문제가 해결되었군요. 이제 모든 데이터를 표준점수로 바꿔 다시 그래프를 그려보겠습니다.
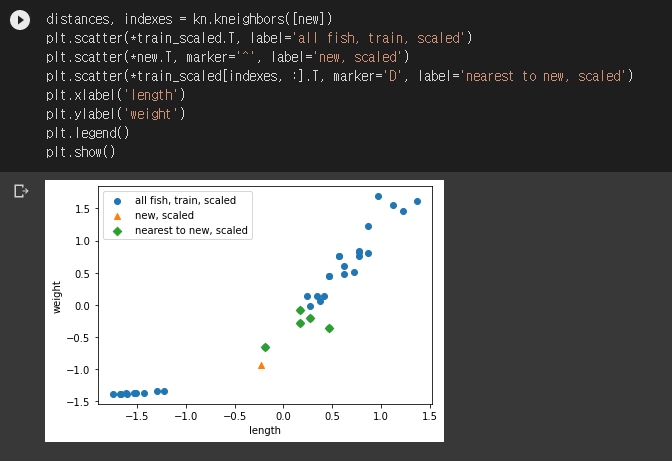
가까운 점 5개가 모두 도미로 잘 찾아졌군요. 만세- 표준점수로 바꿨으므로 그래프는 두 축 모두 0을 중심으로 그려졌다는 것도 확인됩니다.
확인 문제
1. 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은 무엇인가요?
1) 지도 학습
2) 비디오 학습
3) 차원 축소
4) 강화 학습
정답: 1번 지도 학습입니다. 이름 그대로 지도supervision를 해주고 훈련시키는 학습이죠. 반대로 지도(정답) 없이 훈련시키는 방법을 비지도 학습unsupervised learning이라고 부릅니다. 참고로 강화학습은 보상을 최대화하는 방향으로 행동을 선택하도록 훈련시키는 것을 말합니다.
2. 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이라고 부르나요?
1) 샘플링 오류
2) 샘플링 실수
3) 샘플링 편차
4) 샘플링 편향
정답: 4번 샘플링 편향입니다. 이름 그대로 데이터가 편향bias 되어 있다는 뜻입니다. 훈련 세트와 테스트 세트는 전체 데이터의 비율을 그대로 유지하면서 나뉘어져야 합니다. 이 비율이 공정하게 나뉘지 않으면 훈련이 제대로 되지 않을 수 있습니다. 극단적인 경우로, 도미 데이터로만 훈련을 시키면 어떤 생선이 들어와도 모두 도미로 판단하게 됩니다. 컴퓨터가 도미만 알고 있기 때문입니다.
3. 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
1) 행: 특성, 열: 샘플
2) 행: 샘플, 열: 특성
3) 행: 특성, 열: 타깃
4) 행: 타깃, 열: 특성
정답: 2번 행: 샘플, 열: 특성입니다. 행 개수는 샘플 개수입니다. 열 개수는 특성 개수입니다. 생선이 35마리이고 특성이 길이와 무게 2개라면, 입력 데이터는 35 x 2 행렬이 됩니다.
2장 내용정리는 여기서 마치겠습니다. 끝까지 읽어주셔서 고맙습니다.
'혼공머신' 카테고리의 다른 글
| [혼공머신] 5장. 트리 알고리즘: 화이트 와인을 찾아라! (0) | 2022.07.31 |
|---|---|
| [혼공머신] 4장. 다양한 분류 알고리즘: 럭키백의 확률을 계산하라! (0) | 2022.07.24 |
| [혼공머신] 3장. 회귀 알고리즘: 농어의 무게를 예측하라! (0) | 2022.07.17 |
| [혼공머신] 1장. 나의 첫 머신러닝: 이 생선의 이름은 무엇인가요? (0) | 2022.07.09 |
| [혼공머신] 혼공학습단 활동 시작 (0) | 2022.07.03 |