
 CIE chromaticity diagram 이해하기
CIE chromaticity diagram 이해하기
지난 글에서 궁금해했던 CIE color space에 대해 공부해보았습니다. 이 글의 내용 대부분은 아래 영상에서 가져온 것입니다.기록 차원으로 간단히 요약하여 남겨둡니다.잘못된 부분이 있을 수 있습니다. 발견하시면 댓글에 남겨주세요. 글 작성에 도움 주신 바이올린 소나타 님께 감사 말씀 드립니다. Spectral color와 metameric color• 가시광선의 단파장을 사람이 색으로 인식하는데, 그 색을 spectral color라고 부른다. • 사람이 인식하는 색 중에는 단파장으로 만들 수 없는 색도 있다.• 이것을 metameric color라고 부르는데, 자홍색(magenta)이 대표적인 예이다.• 후술하겠지만, RGB 조합으로는 사람이 인식하는 색을 모두 만들어낼 수 없다.• 즉..
 흰색은 어떻게 만들어지는가?
흰색은 어떻게 만들어지는가?
질문을 받았다. 빛을 프리즘으로 분광시키면 빨주노초파남보의 색으로 나뉘는데반대의 경우 왜 빨강, 파랑, 초록 만으로 흰색이 될 수 있는지 궁금합니다.한번도 궁금해본 적이 없는 질문! 이런 질문이 나를 흥분시킨다. 아래는 나름의 리서치 결과이다. Q. 햇빛을 프리즘으로 분리하면 왜 빨주노초파남보가 되는가?• 햇빛은 다양한 파장의 빛으로 구성되어 있음• 그 중 사람이 눈으로 인식하는 영역을 가시광 영역이라고 부르며, 빨강부터 보라까지임• 이 외에 적외선(infrared, IR)과 자외선(ultraviolet, UV)도 햇빛에 포함되어 있음• 즉, 햇빛을 '빨주노초파남보'라고 부르는 것은 온전히 인간의 인식에 의한 것임 Q. 사람은 어떻게 색을 인식하는가?• 사람의 눈에는 세 종류의 원추세포가 있음• L..
 완벽주의를 잘 활용하려면?
완벽주의를 잘 활용하려면?
요즘은 MBTI가 대세(?)이지만 유형 검사는 그것 말고도 더 있습니다. DISC 검사가 그 중 하나인데요. 여러분이 소중히 하지 않고 매일 괴롭히는 허리 디스크가 아니고, 행동 유형을 아래와 같이 4가지로 분류한 것입니다.D: Dominant, 주도형* 목표지향적입니다.* 시키지도 않았는데 앞장서는 사람이 있다면 D형일 가능성이 높습니다.* 그림 아무거나 그리라고 시키면 꼭 과녁을 그립니다.* 잘 되면 타고난 리더이고, 잘못되면 독불장군입니다.* D형이 극혐하는 말이 있습니다. "너는 나대지좀 마."I: Influential, 사교형* 친구가 많은 타입입니다.* 딱 보면 티가 납니다. 모두가 좋아하거든요.* 그림 아무거나 그리라고 시키면 꼭 음표를 그립니다.* 팀의 윤활유 역할인데, 업무능력보다 사교성..
 매트랩에서 텍스트를 컬러풀하게
매트랩에서 텍스트를 컬러풀하게
FileExchange에서 재밌는 함수를 찾았다. 이곳에서 확인할 수 있다. 개발자는 undocumented matlab으로 유명한 Yair Altman. 매트랩의 명령 창 텍스트 출력은 기본적으로 검은 색의 plain text이다. 그나마 하나 있는 자유도는 텍스트를 빨간색으로 할 수 있다는 것인데... cprintf를 이용하면 임의의 색깔로 출력할 수 있다. 게다가 bold체도 되고 밑줄도 된다. 기본적으로 문법은 cprintf(style, format, A1, ..., An) 이다. style만 빼면 fprintf와 동일하며, 동작방식도 완벽히 동일하다. 추가된 것은 style인데, 여기에 색깔, bold 여부, 밑줄 여부를 지정할 수 있다. style에 Text, Keywords, Comm..
 수학에서의 역설
수학에서의 역설
0. 들어가며 수학에서 역설은 흥미로운 주제이다. 듣다 보면 "이게 뭐지...?" 싶은데, 말이 되면서 동시에 말이 안되는 모순을 일으킨다. 그래서 흥미롭다. 생각할 거리를 주기 때문이다. 물론 흥미에서 끝나면 안되고, 해결을 해야 한다. • 그렐링-넬슨의 역설• 도서관 사서의 역설• 이발사의 역설• 베리의 역설• 러셀의 역설• 거짓말쟁이의 역설 이것들은 모두 다른 형태를 띠고 있지만, 곰곰이 따져보면 같거나 비슷한 명제의 다른 표현임을 알 수 있다. 주의: 이 글을 읽다보면 반복되는 단어에 정신이 혼미해질 수 있음 1. 그렐링-넬슨의 역설 (Grelling–Nelson paradox) • 자기서술적인(Autological) 단어는 단어의 의미가 스스로를 설명하는 단어이다.• '짧다'는 짧다. 그래서 '..
 애증의 정규식... 2탄
애증의 정규식... 2탄
이 글은 정규식 삽질의 기록이며, 나중에 내가 같은 패턴을 쓸 일이 있을 때 찾아보기 위함이다. (1탄 보러가기) 0. 요약 • 어떤 텍스트가 '숫자4개_숫자4개' 꼴인지 보려면?~isempty(regexp(str, '^\d{4}_\d{4}$', 'once'))• 여기서\d는 숫자 하나\d{4}는 숫자 4개캐럿은 문자열이 그걸로 시작하는지 확인딸라는 문자열리 그걸로 끝나는지 확인이다. • isempty를 써야 하는 이유는? regexp의 결과로 빈 배열이 나올 수 있기 때문 1. 하려고 했던 것 • 파일명 쓰기 귀찮아서 아무 파일명으로 저장한 이미지 파일들을 일괄로 변경하고 싶었다.• 예를 들어 2024년 6월 1일에 수정한 파일이라면 '2024_0601.png'로 바꾸고 싶다.• 챗gpt가 이런 건 ..
 자연수의 개수와 짝수의 개수가 같다고?
자연수의 개수와 짝수의 개수가 같다고?
자연수의 개수와 짝수의 개수가 같다는 게 무슨 말일까? 명백히 짝수는 자연수의 진부분집합이다. 그렇다면 자연수가 짝수보다 많다고 하는 것이 타당하지 않을까? 하지만 이게 생각만큼 간단한 문제가 아니다. 아래 집합을 보자. 여기, 외로운 과일 네 개가 있습니다. 과일 네 종류를 원소로 갖는 집합이다. 집합의 크기는 4이다. 이 집합을 아래와 같이 바꿨다. 사과 2개는 원소가 2개가 된 것이 아니고, 그냥 사과 2개를 하나로 묶은 것이다. 따라서 위와 같이 바꾼다고 해서 집합의 크기가 바뀌지는 않을 것이다. 원소가 몇 개이든 이 사실은 변함이 없다. 이번엔 아래를 보자. x는 값이 아니라 기호이다. 위 집합은 x0부터 x10까지 11개의 원소를 갖는 집합이다. 이제 각 원소에 2를..
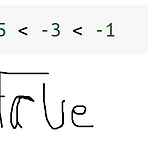 syntax sugar in python
syntax sugar in python
파이썬에는 syntax sugar라는 게 있다. Syntactic sugar라고도 부른다.굳이굳이굳이 번역하자면 문법적 설탕이라고 부를 수 있겠지만,솔직히 끔찍한 번역이다. 파이썬의 문법을 엄밀히 따른다면 아래의 statement는 에러가 떠야 한다. a = 1c = b = a 기호 =(assignment)가 operator가 아니라 statement라서 반환값이 없기 때문이다. (참고) 하지만 에러가 발생하지 않는다. 파이썬에서는 위 statement를 아래와 같이 재해석하기 때문이다. temp = ac = tempb = temp 이걸 chained assignment라고 부른다. 참고로 왼쪽부터 대입한다. (참고) 비슷한 게 하나 더 있다. Chained comparison이다. 이름만 들어도 ..
 왜 numpy에서 5 < ndarray < 15가 허용되지 않는가?
왜 numpy에서 5 < ndarray < 15가 허용되지 않는가?
파이썬에서 숫자는 chained comparison이 되는데 numpy.ndarray는 안된다. 게으른 파이썬 녹화하다가 즉흥적으로 궁금해져서 해봤는데 막혀서 당황했다. 의미적으로는 되어야 할 것 같은데 왜 막아놨지? 궁금해졌다. 챗gpt한테 물어봤으나 뻘소리만 해대길래 검색해봤다. 검색어는 "ndarray chained comparison". 어떤 stackoverflow의 답변을 요약해보면, • PEP 535에서 제안되었으나 연기되어 있는 상태임• 파이썬에서 아래 코드는2 • 아래와 같이 해석됨2 • 논리 연산자 and는 피연산자에 bool을 입힘• 그런데 ndarray는 요소가 2개 이상이면 bool을 입히지 못함 (왜 못하게 해놨지?) • 여튼 해결책으로 bitwise or인 &를 쓰..
 horzcat과 vertcat은 도대체 왜 필요한가?
horzcat과 vertcat은 도대체 왜 필요한가?
예전부터 궁금했다. 행렬을 수평으로 합치고 싶으면 아래처럼 쓰면 되고, >> A = rand(3, 2);>> B = rand(3, 3);>> [A, B]ans = 0.1450 0.3510 0.0760 0.1839 0.0497 0.8530 0.5132 0.2399 0.2400 0.9027 0.6221 0.4018 0.1233 0.4173 0.9448>> 수직으로 합치고 싶으면 아래처럼 쓰면 되는데, >> A = rand(3, 2);>> C = rand(4, 2);>> [A; C]ans = 0.4909 0.9001 0.4893 0.3692 0.3377 0.1112 0.7803 0.096..