
티스토리 뷰

5. CPU 성능 향상 기법
- 나의 학부생 시절에는 컴퓨터 부품을 직접 사서 조립하는 것이 유행이었다.
- 사실 완제품 말고는 그것밖에 방법이 없었다.
- 조립 서비스 같은 것이 없었기 때문이다.
- 특히 서멀 그리스 바르는 것이 정말 쉽지 않았던 기억이 난다.
- 그 와중에 CPU를 더 빠르게 하겠다고
- BIOS 들어가서 오버클럭 활성화시키고
- 그랬다가 컴퓨터 안 켜지기도 했던 기억도 난다.
- 뭐 대단한 걸 하겠다고 그 난리를 쳤을까 싶다.
- CPU는 이미 빠르다.
- 작업 수행의 최소 단위가 나노초 단위이다.
- 하지만 인간의 욕심은 끝이 없다.
- 더 잘 굴리고 싶다!
- 이번 장의 주제는 멀티코어, 멀티스레드이다.
5.1 빠른 CPU를 위한 설계 기법
- 클럭을 높인다고 장땡이 아니다.
- 발열 때문이다.
- 더 좋은 방법이 있으면 좋겠다.
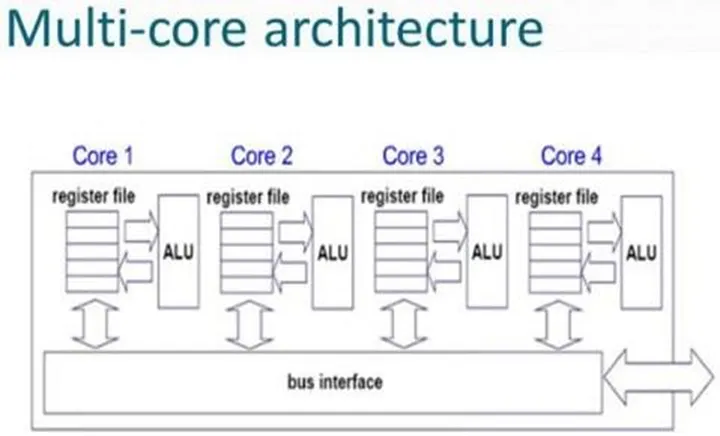
- 한 가지 방법은 뇌를 여러 개 만드는 것이다.
- 이것을 '멀티코어'라고 부른다.
- 앞에서 CPU를 뇌에 비유했었는데,
- 멀티코어는 정말로 ALU, 레지스터, 제어장치의 구성이 여러 개 들어 있다.
출처: https://medium.com/@thatavarthiakash30/recent-advancements-in-multi-core-processors-f5195a615204
- 여러 가지 일을 동시에 처리하는 것을 멀티태스킹이라고 부른다.
- 나는 멀티태스킹이 참 안되는 타입이다.
- 스타크래프트 게이머들을 보면 일꾼 관리, 병력 배치, 전투, 견제 등을 동시에 수행한다.
- 볼 때마다 신기하다.
- 사람의 뇌도 어느 정도는 멀티태스킹이 가능하다.
- CPU의 작업 효율을 높이는 두 번째 방법은
- 멀티태스킹을 흉내낸 멀티스레드이다.
- 여기서 하드웨어적 스레드와 소프트웨어적 스레드를 구분해야 한다.
- 하드웨어적 스레드는 CPU 안에서 여러 작업이 동시에 돌아가는 것이다.
- 핵심은 레지스터에 있다.
- 명령을 수행하기 위해서는 프로그램 카운터, 스택 포인터, 메모리 버퍼 레지스터 등이 필수적인데,
- 이 레지스터 세트를 여러 개 만드는 것이다.
- 그래도 어쨌든 한 번에 한 사이클만 돌 것 같은데, 어떻게 여러 작업을 동시에 수행하는가?
- 이건 다음 절에서 알아본다.
- 소프트웨어적 스레드는 하드웨어와 무관하게,
- 소프트웨어적으로만 작업들을 나눈 것이다.
- 실제로 각 작업을 메모리의 여러 곳에 올려놓고 작업을 수행할 수 있다.
- 이것을 파이썬에서 구현한 것을 여기에서 볼 수 있다.
- 자세한 내용은 운영체제에서 다시 알아본다.
5.1.1 확인 문제
멀티코어 CPU에서 각 "ALU+레지스터들+제어장치" 묶음을 말하는 용어는?
- 답: 코어
코어, 멀티코어, 스레드, 멀티스레드 개념 정리
- 코어
- CPU, 레지스터, 제어장치로 구성된 명령어 처리 부품 세트
- 멀티코어
- 코어가 2개 이상인 CPU의 구성
- 스레드
- 사전적 의미는 '실행 흐름의 단위'이나,
- 좀 더 쉽게 멀티태스킹에서 하나의 태스크라고 볼 수도 있음
- 멀티스레드
- 여러 개의 스레드가 동시에 돌아가는 것
- 하드웨어적 스레드와 소프트웨어적 스레드가 있음
- 코어
5.2 명령어 병렬 처리 기법
- CPU는 바쁘다. 한 순간도 쉬지 않는다.
- 그런데 한번에 한 가지 일만 하느라 바쁘다.
- CPU의 동작 과정을 생각해보면, 모든 과정에서 모든 부품이 바쁘지는 않다.
- 뇌가 바쁠 때가 있고 손이 바쁠 때가 있다.
- 뇌만 바쁠 때는 손이 쉬고 있고,
- 손이 바쁠 때는 뇌가 쉬고 있다.
- 용납할 수 없다! 라는 인간의 욕심의 결과물이
- 이번 절에서 설명할 병렬 처리이다.
명령어 처리 과정을 클럭 단위로 나누면 아래와 같다.
- 명령어 인출 (instruction fetch)
- 명령어 해석 (instruction decode)
- 명령어 실행 (execute instruction)
- 결과 저장 (write back)
컨베이어 벨트 위에 상자(명령어)가 놓여 있고
인출, 해석, 실행, 저장을 담당하는 직원이 있는 모습을 상상해볼 수 있는데
이 컨베이어 벨트를 명령어 파이프라인instruction pipeline이라고 부르고
여러 컨베이어 벨트를 돌리는 것을 명령어 파이프라이닝이라고 부른다.
병렬 처리의 핵심 아이디어는,
인출한 것을 해석하고 실행하고 저장하는 것을 기다리지 않고,
해석으로 넘긴 후 바로 그 다음 명령어를 인출하겠다는 것이다.
즉, 아래와 같이 그림이 그려진다.

출처: https://www.youtube.com/watch?v=328yQc-OLSk
- IF, ID, EX 등은 상기한 명령어 처리 과정의 줄임말이다.
- 병렬 처리는 하이리스크-하이리턴이다.
- 이것을 파이프라인 위험pipeline hazard이라고 부른다.
- 데이터 위험data hazard
- 쉽게 말해 앞선 명령의 결과물이 제대로 되어 있어야 뒤 명령의 결과도 제대로 나오는 상황을 말한다.
- 병렬 컴퓨팅을 하다 보면 종종 발생한다.
- 제어 위험control hazard
- 분기 등으로 인해 프로그램 카운터가 갑자기 바뀌는 상황이다.
- 기본적으로 프로그램 카운터는 다음 주소로 이동하는데
- 이 경우 병렬 처리가 제대로 동작하지 않는다.
- 이것을 미리 예측하고 그 주소를 인출하는 기법을 분기 예측branch prediction이라고 부른다.
- 구조적 위험structural hazard
- 서로 다른 명령어가 동시에 CPU의 부품을 사용하려는 상황이다.
- 자원 위험resource hazard이라고도 부른다.
- 데이터 위험data hazard
- 요즘 CPU는 파이프라인이 여러 개이다.
- 즉, 정말로 인출-해석-실행-저장 여러 개가 동시에 실행된다.
- 이것을 슈퍼스칼라라고 부른다.

출처: https://en.wikipedia.org/wiki/Superscalar_processor
- 슈퍼스칼라 구조로 명령어 처리가 가능한 CPU를
- 슈퍼스칼라 프로세서 또는 슈퍼스칼라 CPU라고 부른다.
5.2.1 비순차적 명령어 처리
- 어느 날인가 택시 대기 줄에 서있었다.
- 택시가 오면 한 명씩 탄다.
- 그런데 내 앞앞 사람이 갑자기 전화를 받는 것이다.
- 택시가 왔는데도 전화 받느라 택시를 안 타고 있다.
- 내 앞사람과 나는 그걸 왜 기다려야 하는가!
- 이건 새치기라고 할 수 없다.
- 굳이 새치기라고 부르려면 합법적 새치기라고 불러야 마땅하다.
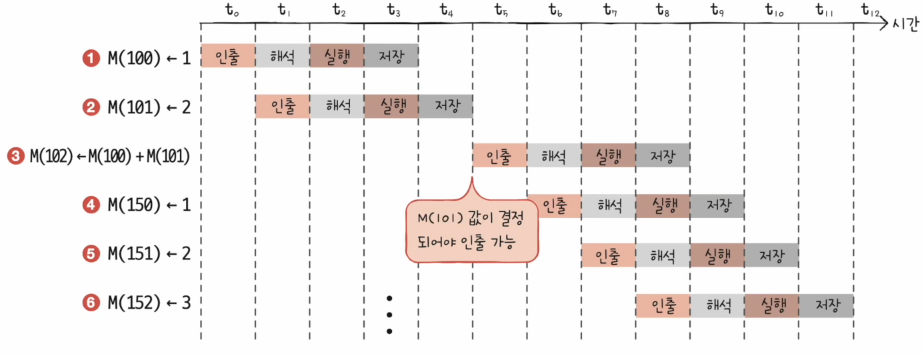
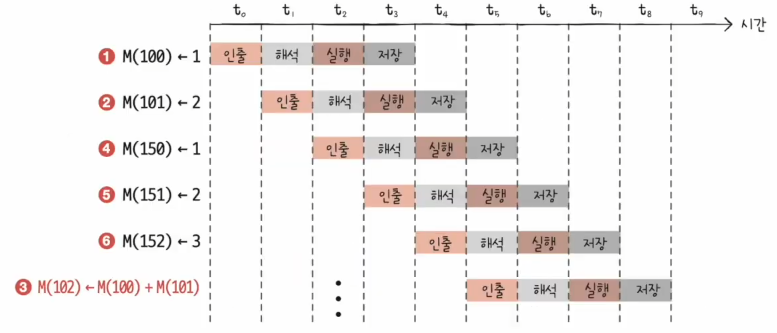
아래와 같은 상황을 생각해보자.
- 명령1: 독립시행
- 명령2: 독립시행
- 명령3: 명령1과 2의 결과를 이용
- 명령4: 독립시행
- 명령5: 독립시행
병렬 처리를 하더라도 어쨌든 순차적으로 시작되어야 한다.
즉, 명령3이 시작하기 전에 명령4를 시작할 수는 없다.
그런데 명령3을 시작하려면 명령1, 2가 끝나기를 기다려야 한다.
출처: https://velog.io/@kio0207/컴퓨터-구조-비순차적실행
- 명령4는 새치기를 하고 싶다!
- 이것을 비순차적 명령어 처리 기법이라고 부른다.
출처: https://velog.io/@kio0207/컴퓨터-구조-비순차적실행
5.3 CISC와 RISC
- 챕터 3의 내용을 잠깐 복기해보자.
- 명령어는 연산코드와 오퍼랜드로 구성된다.
- 연산코드에는 수행할 작업이 적혀 있다.
- 오퍼랜드에는 작업의 대상이 적혀있는데, 주로 주소가 적혀있다.
- CPU 내부에서 이 정보들은 각각의 레지스터로 들어간다.
- 제어장치는 순차적으로 레지스터의 정보들을 CPU로 전달하고, 받고, 내보낸다.
- 이 복잡한 과정들이 수 GHz의 속도로 돌아간다고 생각해보면,
- 컴퓨터가 꼬이지 않고 제대로 돌아간다는 게 신기하게 느껴질 정도이다.
- 게다가 이것들을 병렬로 처리한다!
- 그러기 위해서는 명령어도 대충 만들면 안되고, 안 꼬이게 잘 만들어야 한다.
- 우선 ISA의 개념을 이해해보자.
- ISA는 Instruction Set Architecture의 약자이다.
- 여기에는 명령어의 모든 디테일이 담겨있다.
- 명령어의 형태, 연산, 주소 지정 방식 등
- 즉 ISA는 말하자면 CPU의 언어이다.
- 그리고 이것은 당연히 CPU의 구조에 의존한다.
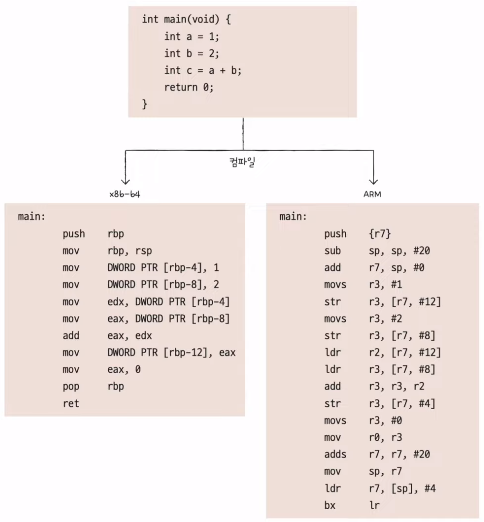
- 인텔 CPU는 x86 또는 x86-64 ISA를 사용한다.
- 애플 CPU는 ARM ISA를 사용한다.
- CPU가 이해하는 언어는 기계어 또는 어셈블리어인데,
- 같은 코드라도 CPU에 따라서(ISA에 따라서) 다르게 번역(컴파일) 된다.
- 명령어 병렬 처리를 도입하기 유리한 ISA에는 양대산맥이 있다.
- CISC와 RISC이다.
- 내가 좋아하는 루빅스 큐브로 비유를 해보고자 한다.
- 큐브의 해법은 다양한데, 크게 초급, 중급, 고급 해법으로 나눠보자.
- 초급 해법
- 솔루션이 많은 단계로 이루어진다.
- 대신 하나의 단계는 길이가 짧은 공식들을 몇 개만 외우면 된다.
- 큐브를 맞추기 위해 돌려야 하는 회전수가 길다.
- 중급 해법
- 솔루션의 단계 수가 줄어든다.
- 대신 하나의 공식이 길어지고, 외워야 할 경우의 수도 많아진다.
- 고급 해법
- 딱 3단계로 구성된다.
- 각 단계마다 경우의 수가 엄청나게 많다.
- 2단계인 OLL은 경우의 수가 60가지 정도 된다.
- 3단계인 PLL은 경우의 수가 30가지 정도 된다.
- 각 경우의 시퀀스도 길다.
- 대신 처음부터 끝까지 회전수는 가장 짧다.
- CISC(Complex Instruction Set Computer)
- 말하자면 큐브의 고급 해법이다.
- 가변 길이 명령어를 활용한다.
- 명령어의 형태, 크기, 기능이 다양하다.
- 즉, 적은 수의 명령어로도 프로그램을 실행할 수 있다.
- x86-64 ISA가 이 방식을 채택하고 있다.
- 장점: 메모리를 아낄 수 있다.
- 단점1: 명령어가 복잡하고 다양하기 때문에 명령어의 크기와 실행 시간이 일정하지 않다.
- 즉, 아래와 같은 상황이 생길 수 있고 파이프라이닝이 어려워진다.
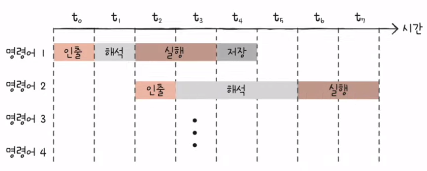
- RISC(Reduced Instruction Set Computer)
- 말하자면 큐브의 초급 해법이다.
- 각 명령어는 짧고, 규격화되어 있고, 1클럭 내외로 실행되는 것을 지향한다.
- 어느 정도냐면, 메모리에 직접 접근하는 명령어가 load, store 2개 뿐이다.
- 고정 길이 명령어를 활용한다.
- 따라서 파이프라이닝이 최적화되어 있다.
- 레지스터를 적극 활용하고, 범용 레지스터 개수도 더 많다.
'혼공컴운' 카테고리의 다른 글
| [혼공컴운] 7장. 보조기억장치 (0) | 2024.07.22 |
|---|---|
| [혼공컴운] 6장. 메모리와 캐시 메모리 (0) | 2024.07.21 |
| [혼공컴운] 4장. CPU의 작동 원리 (0) | 2024.07.14 |
| [혼공컴운] 3장. 명령어 (0) | 2024.07.06 |
| [혼공컴운] 2장. 데이터 (0) | 2024.07.06 |