
티스토리 뷰
2. 데이터
- 컴퓨터는 하드웨어이고, 전기와 소프트웨어로 돌아간다.
- 소프트웨어는 정보이다.
- 정보는 명령어와 데이터로 구성된다.
- 명령어는 "이거 해"라는 문장이고,
- 데이터는 "이거"에 해당하는 재료이다.
- 이번 챕터는 데이터에 대해 다룬다.
- 챕터 제목이 참 짧다.
- 작가 김훈의 간결한 문장이 떠오른다.
- 나 역시 만연체를 쓰지 않도록 항상 조심하고 있다.
2.1 0과 1로 숫자를 표현하는 방법
- "컴퓨터에서 모든 것은 0과 1로 표현된다."
- 분명이 누구나 한번쯤 들어봤을 법한 말이다.
- 그런데 이상하다.
- 지금 내가 쓰고 있는, 여러분이 읽고 있는 이 글씨는 0과 1이 아닌데?
- 파이썬 코드는 영어인데?
- 모든 것이 0과 1이라는게 무슨 말일까?
- 0과 1이 2진수binary임은 어려운 내용이 아니다.
- 책에도 전구로 잘 설명되어 있다.
- 하지만 진짜 궁금한 것은,
- 그것이 실제로 CPU 내에서 무엇이 켜지고(1) 꺼지냐(0)는 것이다.
- 이 얘기는 제대로 하려면 엄청나게 긴 여정이 될 것이다.
- 트랜지스터, 집적회로, 논리게이트 등은 한두 문장으로 쓸 수 있는 내용이 아니다.
- 읽었던 책 중 한 권으로 읽는 컴퓨터 구조와 프로그래밍에서 설명이 좀 되어 있긴 했다.
- 사실 나도 잘 모르고, 지금 당장 중요한 것은 아니므로, 과감히 패스한다.
- 어쨌든 모든 것은 0과 1로 이루어져 있다.
- 숫자는 그냥 2진수로 바꾸면 0과 1로 이루어진다.
- 음수를 만들 때 2의 보수를 쓰는 이유는 간단하다.
- 더해서 0이 되어야 하기 때문이다.
- 여기서 부호 비트의 개념이 등장하게 되는데,
- 자세한 얘기는 여기에 적어두었다.
2.1.1 확인문제
Q. 1101(2)의 2의 보수는?
A. 0과 1을 뒤집고 1을 더한다. 따라서 0011(2)
2.2 0과 1로 문자를 표현하는 방법
- 문제는 문자다.
- '문'이라는 글자를 어떻게 0과 1로 표현할 것인가?
- 다 건너뛰고 딱 2개만 설명한다.
- 아스키 코드와 유니코드.
- 사실 문자를 0과 1로 표현하는 것은 한줄로 설명 가능하다.
- "문자마다 숫자를 부여하자."
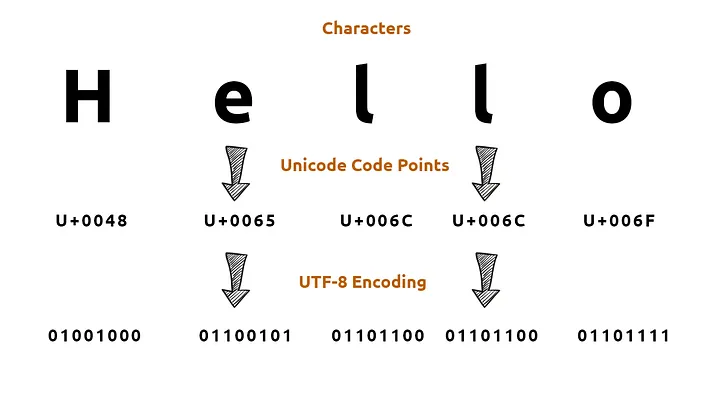
- 우리가 쓴 문자는 부여받은 2진수로 변환되어 CPU로 전달된다.
- 이것을 인코딩enncoding이라고 부른다.
- CPU가 만들어낸, 원래는 문자인 2진수는 다시 문자로 변환되어 우리에게 보여진다.
- 이것을 디코딩decoding이라고 부른다.
- 이제 필요한 것은 딱 하나다. 문자-숫자 변환표.
- 컴퓨터가 막 만들어졌을 때에는 128개의 문자만으로도 충분했다.
- 모든 것은 영어였기 때문이다.
- 이 128개 문자의 변환표를 아스키 코드표라고 부른다.

출처: https://simple.m.wikipedia.org/wiki/File:ASCII-Table-wide.svg
{kind=link}
- 여러 나라들이 각국의 문자를 입력하고 싶었다.
- 훨씬 더 긴 변환표가 필요해졌다.
- 여러 과정을 거쳐, 현재 가장 많이 사용되는 것은 유니코드이다.
- 유니코드를 이용한 문자 인코딩 과정은 조금 복잡하다.
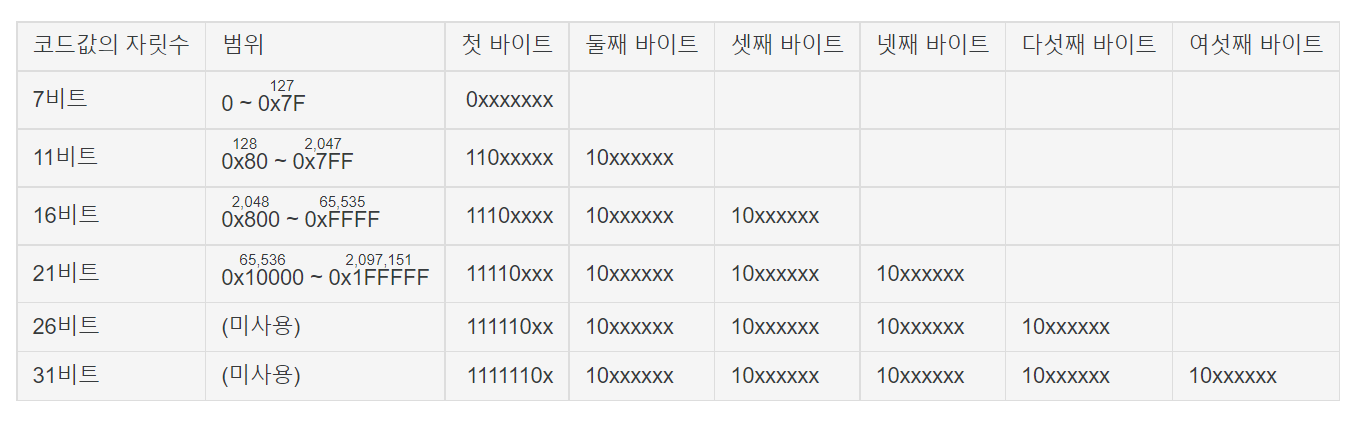
- 유니코드 표에서 문자에 부여된 16진수 값을 찾는다.
- UTF-8 변환표에서 위 1의 16진수가 해당되는 범위를 찾는다.
- 해당 범위의 변환 방식을 참고하여 2진수로 변환한다.
출처: https://velog.io/@ts6938/UTF-8이란-무엇일까
- 예를 들어, '문'은
- 유니코드 표에서 '문'을 찾아보면 'BB38'이다.
- 'BB38'을 2진수로 변환하면 '1011101100111000'이다.
- 'BB38'은 위 UTF-8 표에서 16비트에 해당된다.
- '1011101100111000'을 4개, 6개, 6개로 쪼개서
- '1110xxxx', '10xxxxxx', '10xxxxxx'의 x 위치에 넣는다.
- 한글이 포함된 url을 복사하면 이상하게 복사되는 것을 볼 수 있는데,
- 이것도 한글이 유니코드 인코딩 되기 때문이다.
- url은 2진수로 아니라 16진수로 인코딩 된다.
- url이 2진수로 인코딩 된다고 생각하니 끔찍하다.
- 그래서 '문'은 아래와 같이 인코딩 되고,
- 11101011(2) = EB(16)
- 10101100(2) = AC(16)
- 10111000(2) = B8(16)
- https://namu.wiki/w/MATLAB/문법 -> 이 주소를 복사해보면
- https://namu.wiki/w/MATLAB/%EB%AC%B8%EB%B2%95 -> 이렇게 나온다.
- 사실 한글 url을 인코딩 하지 않고 한글 그대로 복사하는 트릭이 있다.
- 주소창 맨 앞에서 스페이스바를 한 번 치면 된다.
- 자세한 내용은 다른 글에 적어두었다.
- 문자 인코딩에 대한 영상을 하나 붙이면서 2장을 마친다.

'혼공컴운' 카테고리의 다른 글
| [혼공컴운] 6장. 메모리와 캐시 메모리 (0) | 2024.07.21 |
|---|---|
| [혼공컴운] 5장. CPU의 성능 향상 기법 (0) | 2024.07.15 |
| [혼공컴운] 4장. CPU의 작동 원리 (0) | 2024.07.14 |
| [혼공컴운] 3장. 명령어 (0) | 2024.07.06 |
| [혼공컴운] 1장. 컴퓨터 구조 시작하기 (0) | 2024.07.04 |
댓글