
티스토리 뷰
for문은 보통 다음의 Code 1과 같은 방법으로 많이 사용됩니다.
% Code 1
%
% For a given vector, generate
% a new vector whose element is
% 1 when the element of the given
% vector at the same position is
% greater than 0.5, otherwise 0.
%
% 벡터 a가 주어졌을 때, a의 각 요소가
% 0.5보다 크면 1, 그렇지 않으면 0인,
% a와 크기가 같은 새 벡터를 생성하라.
a = rand(1,10);
b = zeros(size(a));
for i = 1:length(a)
if a(i) > 0.5
b(i) = 1;
end
end즉, 벡터 a의 길이만큼 반복문을 수행하고 싶을 때 아래의 패턴이 됩니다.
% Code 2
for i = 1:length(a)
...
...
end하지만 꼭 이 패턴으로 쓸 필요는 없습니다. 위 코드는 아래처럼 짜도 동일하게 동작합니다.
% Code 3
v = 1:length(a);
for i = v
...
...
endCode 3에서는 1:length(a)를 미리 v로 만들어두고, for문을 시작할 때 i=v로 간단하게 끝냈습니다. 즉, Code 2에서 for문에 쓰인 1:length(a)는 for문에 쓰는 특별한 표현식이 아니라, 단순히 행벡터를 만드는 표현식이라는 의미입니다. 이제 for문은 아래처럼 해석할 수 있습니다.
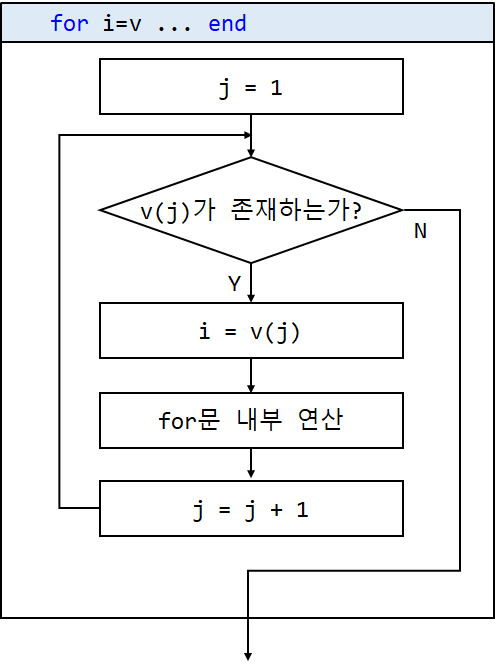
위 그림의 j는 코드에서는 등장하지 않습니다. 매트랩 내부적으로 j를 증가시키며 v에서 요소를 하나씩 꺼내오는 것입니다. 또는 아래처럼 해석할 수도 있겠군요. (Y/N의 방향이 바뀐 것에 주의하시기 바랍니다.)

어느 방식이든 v에서 값을 가져올 수만 있으면 for문이 동작하므로, 이제 Code 1은 아래처럼 쓸 수도 있습니다.
a = rand(1,10);
% Code 4-1
% append new element
% for every iteration
b = [ ];
for i = a
if i > 0.5
b = [b 1];
else
b = [b 0];
end
end
% Code 4-2
% define the index j and
% increase for every iteration
b = zeros(size(a));
j = 1;
for i = a
if i > 0.5
b(j) = 1;
else
b(j) = 0;
end
j = j + 1;
endb에 값을 넣는 것은 if문을 쓰지 않고도 가능하지만, 여기서는 for문의 로직만을 보기 위해 생략하도록 하겠습니다. 위 방식의 아쉬운 점은, 인덱스와 값을 동시에 쓸 수 없다는 점입니다. 즉, for문 안에서 인덱스 j와 a(j)를 한번에 처리할 수 없습니다. Code 4-1에서는 j를 만들지 않았지만 대신 b의 크기를 미리 할당할 수 없으므로, a의 크기가 큰 경우 속도가 느려집니다. Code 4-2에서는 번거롭게 j를 만들어서 써야하니, 맨 처음 코드인 Code 1보다 나은 점이 보이지 않습니다. (매트랩에는 파이썬의 enumerate와 같은 기능이 없습니다.)
그럼 이런 방식은 언제 유리할까요? 아래는 난수 100개를 생성 후, j번째 난수가 0.5보다 클 때만 myfunc() 함수를 실행하는 코드입니다.
myfunc = @() fprintf('BIG!\n');
a = rand(1,100);
% Code 5-1
% using both index and value
for i = 1:length(a)
if a(i) > 0.5
myfunc();
end
end
% Code 5-2
% using value only
for i = a
if i > 0.5
myfunc();
end
endCode 5-2가 Code 5-1보다 조금 더 간결한 것을 볼 수 있습니다. 사실 Code 5-2와 파이썬의 for문과 거의 같습니다. 사족이지만 위 그림 2도 파이썬의 for문 동작방식을 거의 그대로 설명한 것입니다.
cell 배열도 각 요소가 cell인 "행렬"이기 때문에 위와 같은 식으로 사용할 수 있습니다. 단, cell은 숫자와 달리 사칙연산이나 비교연산자를 쓸 수 없으므로 cell을 벗겨줘야 합니다.
myfunc = @() fprintf('BIG!\n');
a = num2cell(rand(1,10));
% Code 5-3
% using value only from cell array
for i = a
if i{1} > 0.5
myfunc();
end
end
for문의 동작과 관련하여 몇가지 알아두면 좋은 점이 있습니다. 아래와 같이 for문 안에서 i 값을 바꾸면 어떻게 될까요?
% Code 6
v = 1:3;
for i = v
disp(['i = ', num2str(i)])
i = 0;
disp(['i = ', num2str(i)])
endi 값을 바꾼 것이 for문에 영향을 줄까요? 결과를 보면...
i = 1
i = 0
i = 2
i = 0
i = 3
i = 0영향을 주지 않습니다. for문 안에서 잠시 i 값이 바뀌었지만, 어차피 한번의 iteration이 끝나면 v에서 새로 값을 받아오기 때문입니다. 그럼 아래는 어떨까요? 아예 v를 loop 도중에 바꿔보았습니다.
% Code 7
v = 1:3;
for i=v
disp(['i = ', num2str(i)])
disp(['v = ', num2str(v)])
v = v + 10;
disp(['v = ', num2str(v)])
endi 값을 가져올 v를 바꿔버렸으니 i도 바뀐 v에서 값을 가져올까요? 결과를 보면,
i = 1
v = 1 2 3
v = 11 12 13
i = 2
v = 11 12 13
v = 21 22 23
i = 3
v = 21 22 23
v = 31 32 33loop 안에서 v를 바꾸든 말든 i는 항상 for문을 시작할 때의 v에서 값을 가져옴을 알 수 있습니다. v를 인덱스로 사용할 수도 있으니, for문을 일단 시작한 이후에는 v는 바뀌지 않도록 설계된 것으로 유추할 수도 있겠습니다.
마지막으로 한가지 유의할 점이 있습니다. 제가 앞에서 "for문에 쓰인 1:length(a)는 for문에 쓰는 특별한 표현식이 아니라, 단순히 행벡터를 만드는 표현식"이라고 말했습니다. 포인트는 "행"벡터라는 점입니다. 아래와 같은 for문에서
for i=v
...
...
endi가 가져오는 것은 사실 v의 j번째 값 v(j)가 아니라, v의 j번째 열 v(:,j)가 됩니다. (행렬의 인덱스를 표현하는 두 가지 방식에 대해서는 이 링크를 참고해주세요.) 즉, 그림 1과 2는 사실 아래와 같이 설명해야 더 정확합니다. (v가 3차원 이상인 경우는 표기가 약간 달라져야 하지만, 여기서는 생략하도록 하겠습니다.)
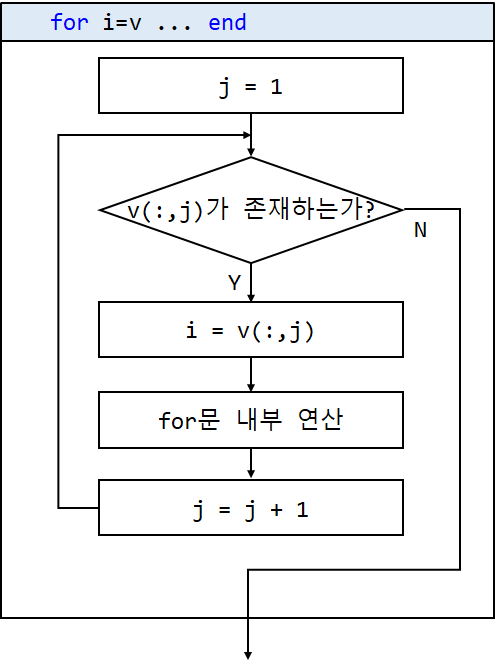

지금까지 나온 예제는 v가 행벡터였으므로 v의 j번째 열이 스칼라가 되고 코드 동작에 문제가 없었습니다. 하지만 v가 2개 이상의 행을 가진 행렬이라면 부등호를 사용할 때 주의해야합니다. 대신 매트랩의 이러한 특이한 for문 동작방식은 활용만 잘 한다면 더 깔끔한 코드 작성에 도움이 됩니다.
지금까지 매트랩의 for문 동작방식을 살펴보았습니다.
- 게으른 맽랩
'matlab' 카테고리의 다른 글
| 매트랩에서의 array unpacking (2) | 2020.07.19 |
|---|---|
| cell array의 특이한 동작 (0) | 2020.07.14 |
| 실수로 에디터 창을 닫았나요? 당황하지 않으셔도 됩니다. (2) | 2020.06.17 |
| 로또 프로그램 (0) | 2020.06.15 |
| 관련 m파일들을 모아서 압축파일을 만들어주는 depfuns2zip (2) | 2020.06.14 |