matlab
horzcat과 vertcat은 도대체 왜 필요한가?
게으른 the lazy
2024. 5. 26. 00:14
예전부터 궁금했다. 행렬을 수평으로 합치고 싶으면 아래처럼 쓰면 되고,
>> A = rand(3, 2);
>> B = rand(3, 3);
>> [A, B]
ans =
0.1450 0.3510 0.0760 0.1839 0.0497
0.8530 0.5132 0.2399 0.2400 0.9027
0.6221 0.4018 0.1233 0.4173 0.9448
>>
수직으로 합치고 싶으면 아래처럼 쓰면 되는데,
>> A = rand(3, 2);
>> C = rand(4, 2);
>> [A; C]
ans =
0.4909 0.9001
0.4893 0.3692
0.3377 0.1112
0.7803 0.0965
0.3897 0.1320
0.2417 0.9421
0.4039 0.9561
>>
도대체 horzcat과 vertcat은 왜 필요한가? 괄호만으로 되는데 왜 함수를 써야 하는가?
검색은 귀찮아서(...) 챗gpt에게 물어봤다. 아래는 답변을 정리한 것이다.
1. 가독성
• "괄호를 쓰는 것보다 함수를 쓰는 것이 가독성이 높다."
• 납득이 간다. 아무래도,
[A, B]
보다는
horzcat(A, B)
가 더 잘 보인다. 컴마인지 세미콜론인지 구별하는 것보다 horz인지 vert인지 구별하는 것이 더 쉽다.
• 이것과 비슷한 상황이 있다. 문자열(char array)을 이어붙일 때,
>> s1 = 'matlab';
>> s2 = 'fun';
>> [s1, ' is ', s2]
ans =
'matlab is fun'
>>
보다는
>> append(s1, ' is ', s2)
ans =
'matlab is fun'
>>
라고 쓰면 가독성이 높아진다. (나만 그런가?)
2. Mixed concatenation
위 1의 연장선상에 있는 내용이다. 구구절절 설명보다 예제로 대신한다.
>> horzcat(B, vertcat(C, C))
ans =
0.4899 0.5005 0.0424 0.8181 0.7224 0.6596
0.1679 0.4711 0.0714 0.8175 0.1499 0.5186
0.9787 0.0596 0.5216 0.8181 0.7224 0.6596
0.7127 0.6820 0.0967 0.8175 0.1499 0.5186
>>
3. Dynamic concatenation
셀 배열에는 특별한 인덱싱 방법이 있다. 이 방법으로 셀 배열의 각 원소를 한방에 분리할 수 있다. 자세한 내용은 이 글을 보자.
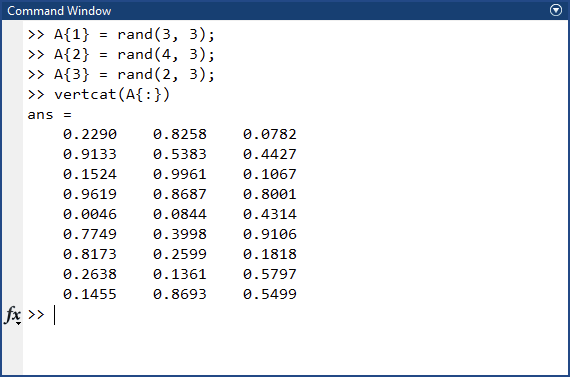
>> A{1} = rand(3, 3);
>> A{2} = rand(4, 3);
>> A{3} = rand(2, 3);
>> A
A =
1×3 cell array
{3×3 double} {4×3 double} {2×3 double}
>> A{:}
ans =
0.3507 0.5502 0.2077
0.9390 0.6225 0.3012
0.8759 0.5870 0.4709
ans =
0.2305 0.1707 0.9234
0.8443 0.2277 0.4302
0.1948 0.4357 0.1848
0.2259 0.3111 0.9049
ans =
0.9797 0.1111 0.4087
0.4389 0.2581 0.5949
>>
즉, A{:}라고 쓰면 A{1}, A{2}, A{3}라고 쓰는 것과 같다. 이것을 horzcat과 vertcat에 활용할 수 있다.
>> vertcat(A{:})
ans =
0.3507 0.5502 0.2077
0.9390 0.6225 0.3012
0.8759 0.5870 0.4709
0.2305 0.1707 0.9234
0.8443 0.2277 0.4302
0.1948 0.4357 0.1848
0.2259 0.3111 0.9049
0.9797 0.1111 0.4087
0.4389 0.2581 0.5949
>>
끗.